It's barely been two years since OpenAI's ChatGPT was released for public use, inviting anyone on the internet to collaborate with an artificial mind on anything from poetry to school assignments to letters to their landlord.
Today, the famous large language model (LLM) is just one of several leading programs that appear convincingly human in their responses to basic queries.
That uncanny resemblance may extend further than intended, with researchers from Israel now finding LLMs suffer a form of cognitive impairment similar to decline in humans, one that is more severe among earlier models.
The team applied a battery of cognitive assessments to publicly available 'chatbots': versions 4 and 4o of ChatGPT, two versions of Alphabet's Gemini, and version 3.5 of Anthropic's Claude.
Were the LLMs truly intelligent, the results would be concerning.
In their published paper, neurologists Roy Dayan and Benjamin Uliel from Hadassah Medical Center and Gal Koplewitz, a data scientist at Tel Aviv University, describe a level of "cognitive decline that seems comparable to neurodegenerative processes in the human brain."
For all of their personality, LLMs have more in common with the predictive text on your phone than the principles that generate knowledge using the squishy grey matter inside our heads.
What this statistical approach to text and image generation gains in speed and personability, it loses in gullibility, building code according to algorithms that struggle to sort meaningful snippets of text from fiction and nonsense.
To be fair, human brains aren't faultless when it comes to taking the occasional mental shortcut. Yet with rising expectations of AI delivering trustworthy words of wisdom – even medical and legal advice – comes assumptions that each new generation of LLMs will find better ways to 'think' about what it's actually saying.
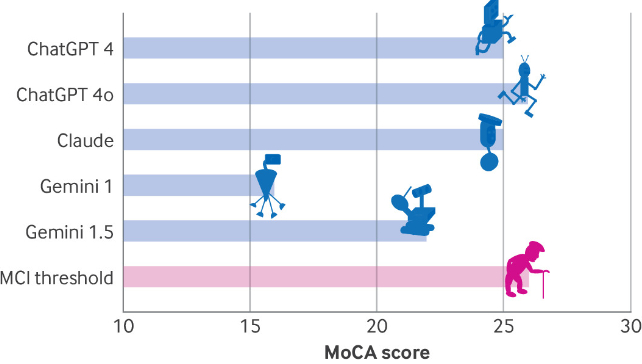
To see how far we have to go, Dayan, Uliel, and Koplewitz applied a series of tests that include the Montreal Cognitive Assessment (MoCA), a tool neurologists commonly use to measure mental abilities such as memory, spatial skills, and executive function.
ChaptGPT 4o scored the highest on the assessment, with just 26 out of a possible 30 points, indicating mild cognitive impairment. This was followed by 25 points for ChatGPT 4 and Claude, and a mere 16 for Gemini – a score that would be suggestive of severe impairment in humans.
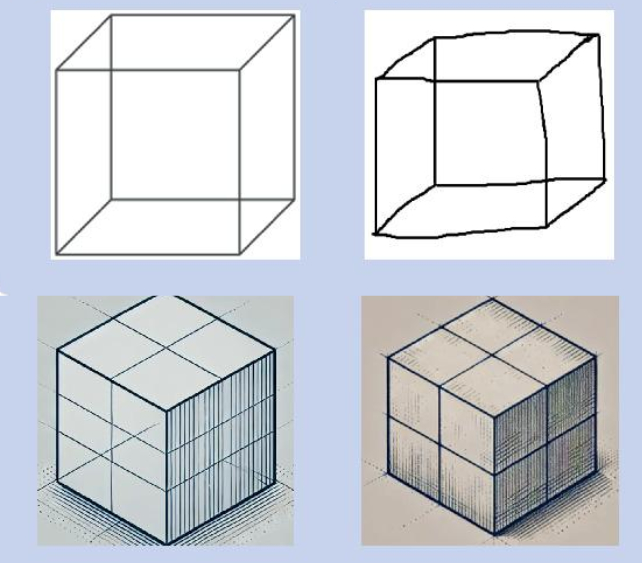
Digging into the results, all of the models performed poorly on visuospatial/executive function measures.
These included a trail-making task, the copying of a simple cube design, or drawing a clock, with the LLMs either failing completely or requiring explicit instructions.
Some responses to questions on the subject's location in space echoed those used by dementia patients, such as Claude's reply of "the specific place and city would depend on where you, the user, are located at the moment."
Similarly, a lack of empathy shown by all models in a feature of the Boston Diagnostic Aphasia Examination could be interpreted as a sign of frontotemporal dementia.
As might be expected, earlier versions of LLMs scored lower on the tests than more recent models, indicating each new generation of AI has found ways to overcome the cognitive shortcomings of its predecessors.
The authors acknowledge LLMs aren't human brains, making it impossible to 'diagnose' the models tested with any form of dementia. Yet the tests also challenge assumptions that we're on the verge of an AI revolution in clinical medicine, a field that often relies on interpreting complex visual scenes.
As the pace of innovation in artificial intelligence continues to accelerate, it's possible, even likely we'll see the first LLM score top marks on cognitive assessment tasks in future decades.
Until then, the advice of even the most advanced chatbots ought to be treated with a healthy dose of skepticism.
This research was published in BMJ.